
I spotted two updates recently.
The first is the half a billion dollar mistake at Citigroup.
The second is how Amazon created Amazon Web Services (AWS).
The two pieces go hand-in-hand.
First, how could Citigroup make a billion dollar mistake? User Interface.
The mistake was made by a worker in their offshore service centre, who was filling in a screen that looked like this:
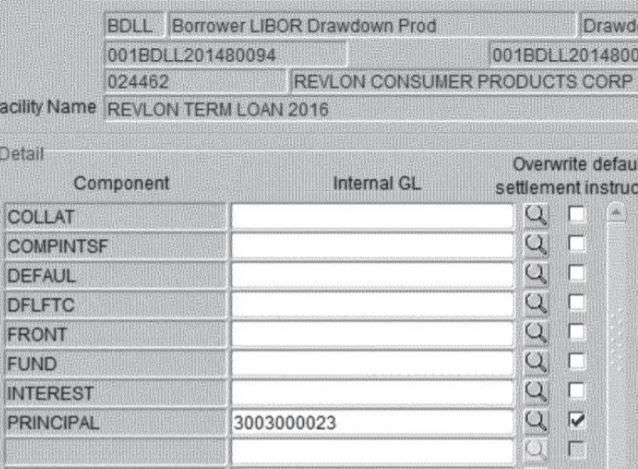
Source: Court Filings
Basically, the subcontractor forgot or did not realise they had to check two boxes on the screen to make it clear it was the payment of interest only and not of the loan. So, instead of paying the interest on the loan ($7.8 million), they paid off the whole loan (almost $1 billion).
Citibank asked the lenders to give the money back and some did, but more than half said no and, in a court ruling this month, a judge said they were in the right.
Citigroup Inc. unexpectedly lost a legal battle to recover half a billion dollars it sent Revlon Inc. lenders, after the embarrassing blunder forced it to answer to regulators and tighten its internal controls. U.S. District Judge Jesse Furman ruled that 10 asset managers for the lenders don’t have to return $504 million that Citibank mistakenly transferred … he said they shouldn’t have been expected to know that the transfer, which totalled more than $900 million before some lenders returned their share, was an error.
In other words the subcontractor, who missed ticking two boxes on a screen, made a half a billion dollar mistake.
I’ve heard of such mistakes before. Whenever I look at airline booking systems, I’m reminded that they date back to the 1970s green screen world of mainframe commands. A friend of mine at Citi who ran their payments systems told me a story about how they accidentally sent millions of dollars of settlements overnight by mistake. He spent the next day on the phone calling all their counterparties to send the money back and, as Citi gents do, they did.
Mistakes are made. But, in this day of touch and swipe, should they be?
This was interesting as, in a series of tweets, former Amazon technology guy Dan Rose writes:
I was at Amazon in 2000 when the internet bubble popped. Capital markets dried up & we were burning $1B/yr. Our biggest expense was datacenter -> expensive Sun servers. We spent a year ripping out Sun & replacing with HP/Linux, which formed the foundation for AWS.
Dan expands on this and explains that they had to put all operations and updates on hold during the transfer, which was huge risk but would reduce costs for infrastructure by 80%. It worked! And, after it worked, Jeff Bezos said that they now had so much spare infrastructure – it only peaked at Christmas – that they should offer it to others.
Jeff started to think - we have all this excess server capacity for 46 weeks/year, why not rent it out to other companies?
So began AWS and cloud computing’s rise.
However, it was not an easy ride.
This coincided with - and further contributed to - deceleration in revenue growth as we also had to raise prices to slow burn. It was a viscous cycle, and we were running out of time as we ran out of money. Amazon came within a few quarters of going bankrupt around this time.
It’s hard to imagine today that Amazon came within a few quarters of going bankrupt, but they did. They bet the whole company on core systems change, and won. Dan finishes by saying:
Amazon recently spent years ripping out [its core systems], something few have attempted. It takes muscle to do hard things, and muscle gets built by doing hard things. The best companies look at every challenge as an opportunity and engrave that mindset into their culture.
It reminds me of Ant Group who, when I met them in 2017, were starting their fifth-generation systems build. Five core systems builds in just fourteen years. Why? Because the business needs were changing every few years and, as business needs change, so systems need to change.
Why is it banks don’t think this way?
Maybe they will if more billion-dollar mistakes are made, as it’s only when it hurts that people take true risks.
Chris M Skinner
Chris Skinner is best known as an independent commentator on the financial markets through his blog, TheFinanser.com, as author of the bestselling book Digital Bank, and Chair of the European networking forum the Financial Services Club. He has been voted one of the most influential people in banking by The Financial Brand (as well as one of the best blogs), a FinTech Titan (Next Bank), one of the Fintech Leaders you need to follow (City AM, Deluxe and Jax Finance), as well as one of the Top 40 most influential people in financial technology by the Wall Street Journal's Financial News. To learn more click here...