I’m no expert on such matters, but a friend of mine was talking about different tools for different times and how they use certain technologies for different services.
In particular their interests are data visualisation techniques and how these can identify fraudulent activity or improve investment strategies.
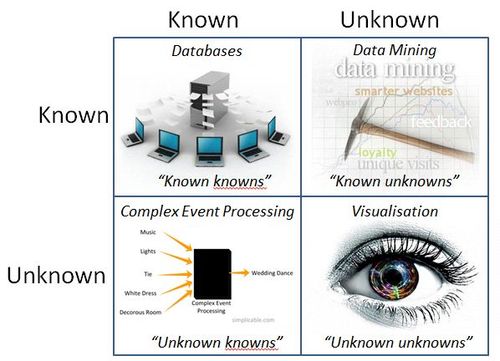
He equated it to the Donald Rumsfeld knowns and unknowns, with basic relational databases dealing with known knowns, data mining with known unknowns, complex events processing with unknown knowns and visualisation with unknown unknowns.
It moves a little beyond my ability with technology to really get this, except that there’s this constant stream of data these days, often referred to as 'big data'.
Data is everywhere, streaming across social networks, banking systems, commercial ecosystems and government intelligence services.
All of this data – gigabytes, petabytes and exabytes of it – is growing daily and exponentially.
There’s too much data.
With all of this data something or someone needs to be able to crunch through it, analyse it and see patterns within it.
Cloud computing helps, as it allows an organisation to sift through terabytes of data in seconds without the internal processing power required to do this, but it’s more than just processing power.
It’s the intelligence to discover.
And that’s why this discussion helped as you can apply massively parallel processing, virtualisation and grid to this tsunami of data, but without a map to see what’s important and what is not, it’s pretty worthless.
So here’s a simple map (doubleclick the image for larger version):
Be interested to see if folks agree whether this covers the bases or not.
Chris M Skinner
Chris Skinner is best known as an independent commentator on the financial markets through his blog, TheFinanser.com, as author of the bestselling book Digital Bank, and Chair of the European networking forum the Financial Services Club. He has been voted one of the most influential people in banking by The Financial Brand (as well as one of the best blogs), a FinTech Titan (Next Bank), one of the Fintech Leaders you need to follow (City AM, Deluxe and Jax Finance), as well as one of the Top 40 most influential people in financial technology by the Wall Street Journal's Financial News. To learn more click here...